?log
help(log)Introduction to R
with the tidyverse
Monday, the 2th of March, 2026
Learning objectives
You will learn to:

- specificities
- Community
- Package ecosystem
- Vectorization
- Opinionated tidyverse
- Data types
- Data structures
What is really?
![]()

is a shorthand for “GNU R”:
- An interactive programming language derived from S (J. Chambers, Bell Lab, 1976)
- Appeared in 1995, created by Ross Ihaka and Robert Gentleman, University of Auckland, NZ
- v1.0.0 released 29th Feb. 2000
- Focus on data analysis and plotting
- is also shorthand for the ecosystem around this language
- Book authors
- Package developers
- Ordinary useRs
Learning to use will make you more efficient and facilitate the use of advanced data analysis tools
Why using R?
![]()
- It’s free! and open-source
- Easy to install / maintain
- Multi-platform ( Windows, macOS, GNU/Linux)
- Can process big files and analyse huge amounts of data (db tools)
- Integrated data visualization tools, even dynamic
shiny - Fast, and even faster with C++ integration via Rcpp or cpp11.
- Easy to get help, welcoming community
- stackoverflow with a lot of tags like r, ggplot2 etc.
- rbloggers
- R ladies
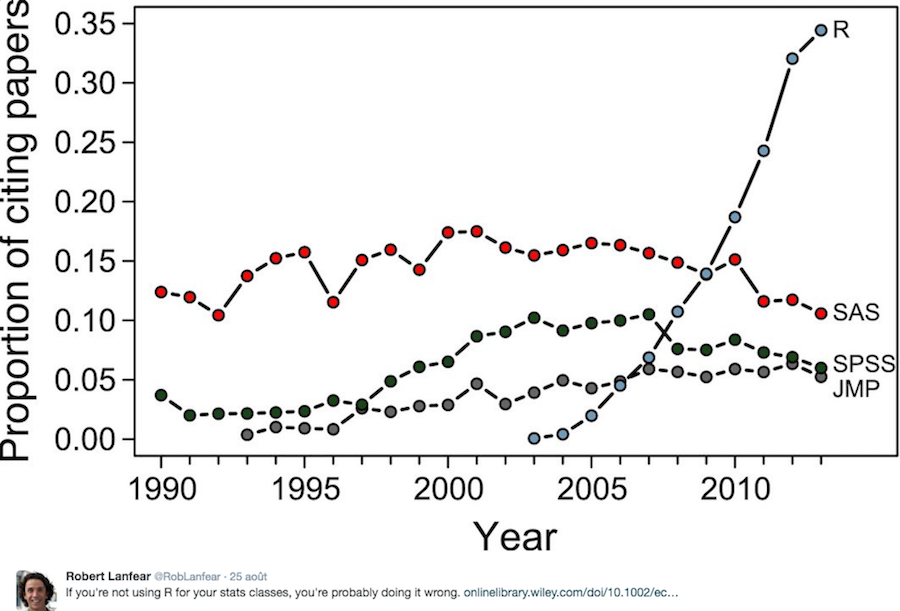
Constant trend in use for interactive stats environments
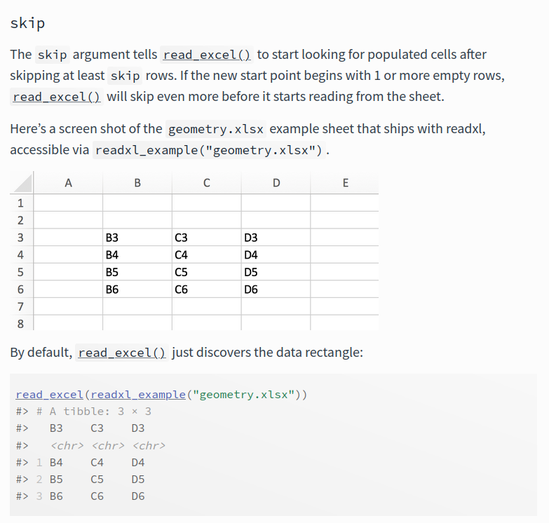
Help pages
2 possibilities for manual pages.
Sadly, manpages are often unhelpful, vignettes or articles better described workflow (below readxl website).
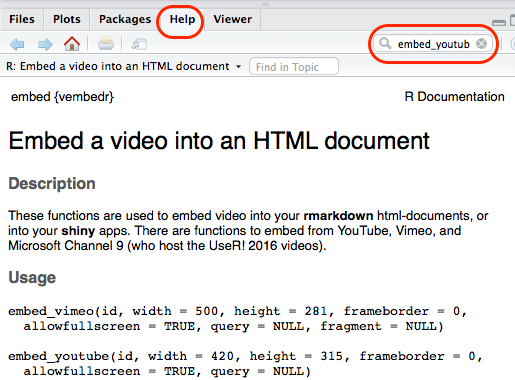
In Rstudio, the help page can be viewed in the bottom right pane

The ambiguity [of the S language] is real and goes to a key objective: we wanted users to be able to begin in an interactive environment, where they did not consciously think of themselves as programming. Then as their needs became clearer and their sophistication increased, they should be able slide gradually into programming, when the language and system aspects would become more important.
— John Chambers, “Stages in the Evolution of S”
Tidyverse origin
Hadley Wickham is Chief Scientist at Posit
- Coined the tidyverse at userR meeting in 2016
- Developed and maintains most of the core tidyverse packages
- 25 years history written down in this document

We think the tidyverse is better, especially for beginners. It is:
- Relatively recent (both an issue and an advantage)
- Becomes stable
- Allows doing powerful things quickly
- Unified (see bookdown on tidyverse design)
- Consistent, one way to do things
- Give strength to learn base R
Tidyverse, core packages
2022: lubridate joined the core
Tidyverse features introduced to base
| Construct | Base | Version | |
|---|---|---|---|
| Strings read as factors | tibbles |
Default | v4.0 |
c(factor("a"), factor("b")) |
[1] a b |
Was [1] 1 1 |
v4.1 |
| Pipe | %>% |
|> |
v4.1 |
| Lambda | ~ .x |
\(x) |
v4.1 |
| Placeholder in pipe | . |
_ |
v4.2 |
| Unnamed placeholder | list(a = 1) %>% .$a |
list(a = 1) |> _$a |
v4.3 |
NULL assignment |
rlang:: |
|
v4.4 |
| Dataset | palmerpenguins::penguins |
penguins |
v4.5 |
Binding names to values: an object has no name
In #rstats, it's surprisingly important to realise that names have objects; objects don't have names pic.twitter.com/bEMO1YVZX0
— Hadley Wickham (@hadleywickham) May 16, 2016
Vector binds to the name x
x <- 1:3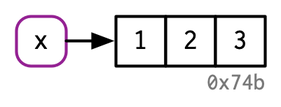
Same vector is also bind to the name y
y <- x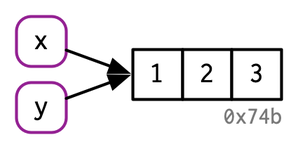
Efficient management of the memory. Names are pointers to memory addresses.
Hierarchy
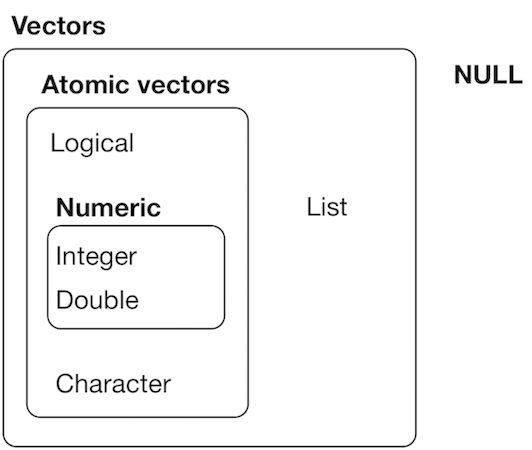
is.vector(c("a", "c"))[1] TRUEis.vector(list(a = 1))[1] TRUEis.atomic(list(a = 1))[1] FALSEis.data.frame(list(a = 1))[1] FALSE