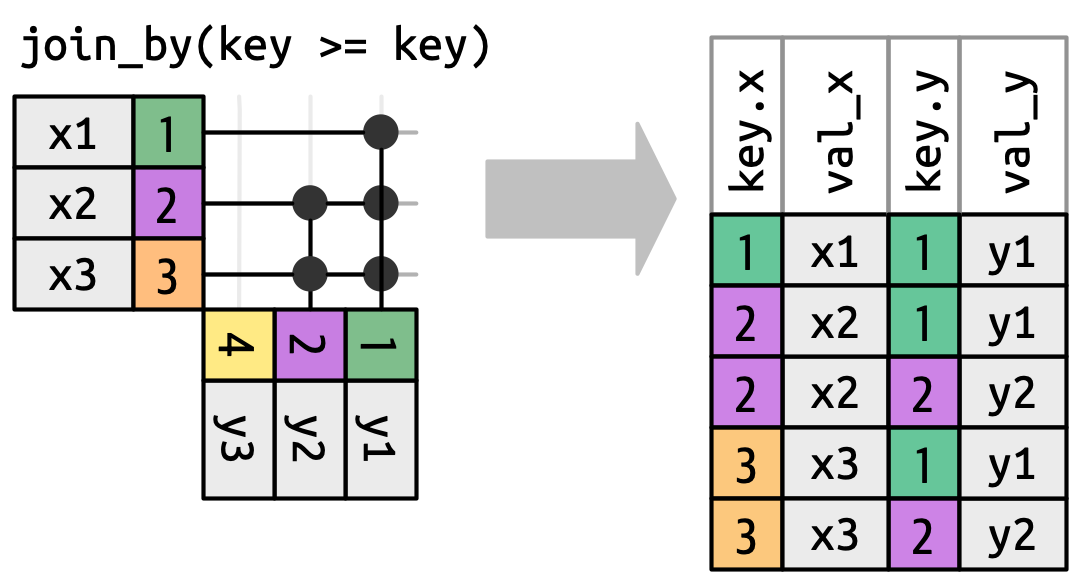
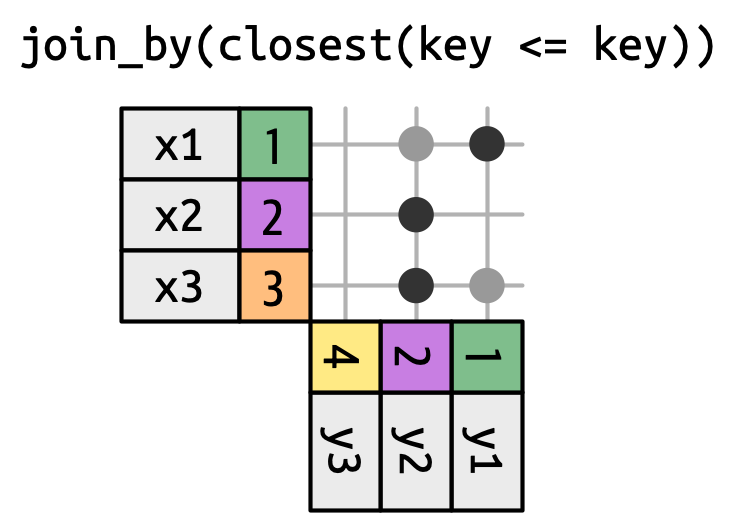
Joins for tables
dplyr
Tuesday 14 April, 2026
Relational operations
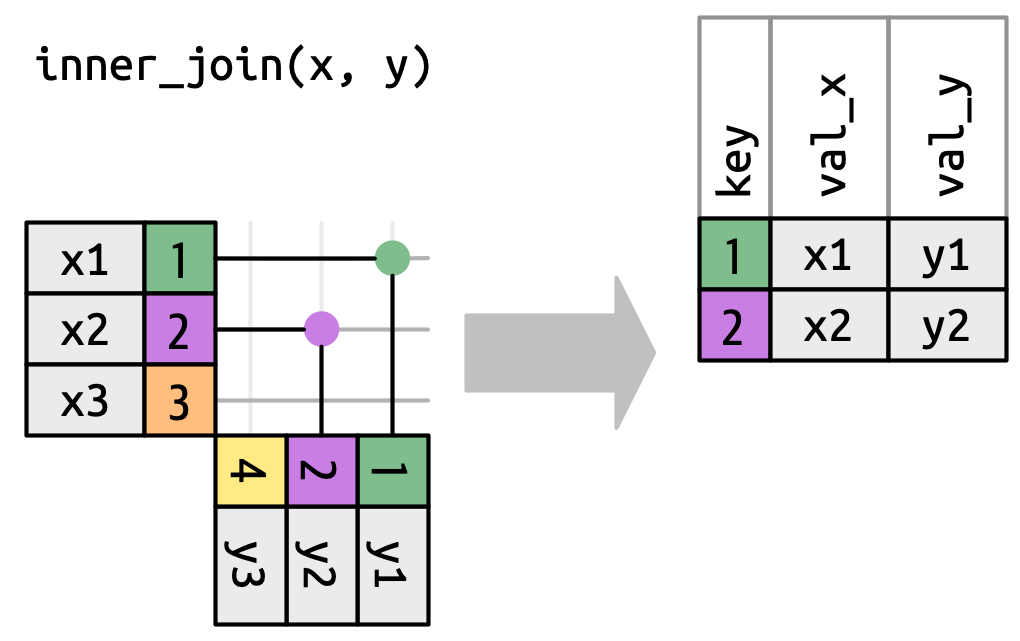
Combining the two tables
Inner join
Error! no common key.
inner_join(coffee_drinkers,
subject_mood)Error in `inner_join()`:
! `by` must be supplied when `x` and `y` have no common variables.
ℹ Use `cross_join()` to perform a cross-join.Provide the correspondences
inner_join(coffee_drinkers,
subject_mood,
by = join_by(student == subject))# A tibble: 3 × 6
student coffee_shots condition gender mood_pre mood_post
<dbl> <dbl> <chr> <chr> <dbl> <dbl>
1 21 1 control female 68 NA
2 23 4 control female 78 NA
3 28 2 stress male 53 68Initial tables are not preserved, but mutated
Mutating joins, overview
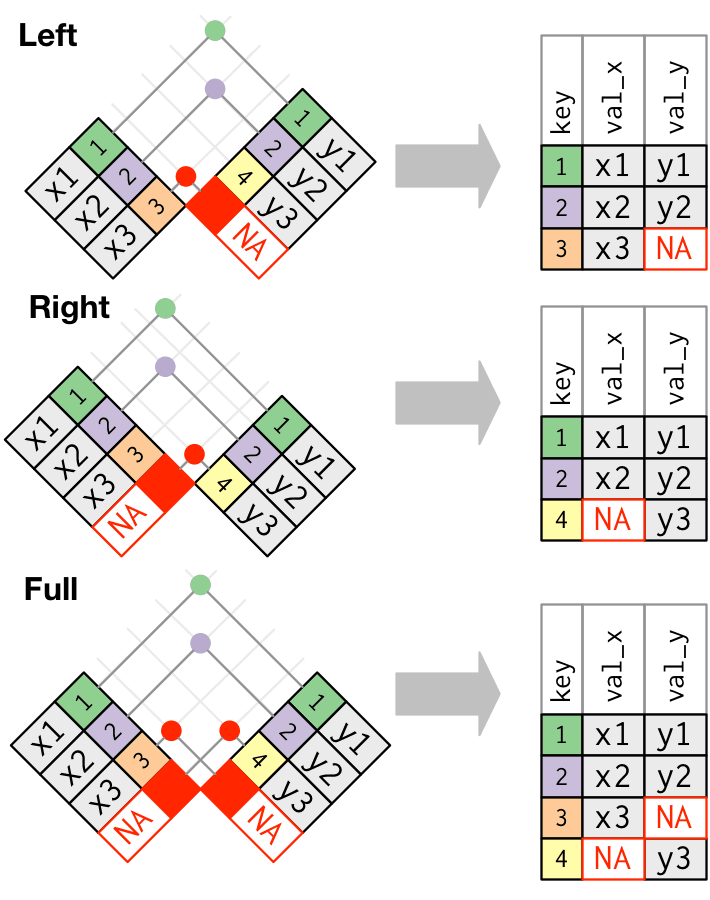
Left join
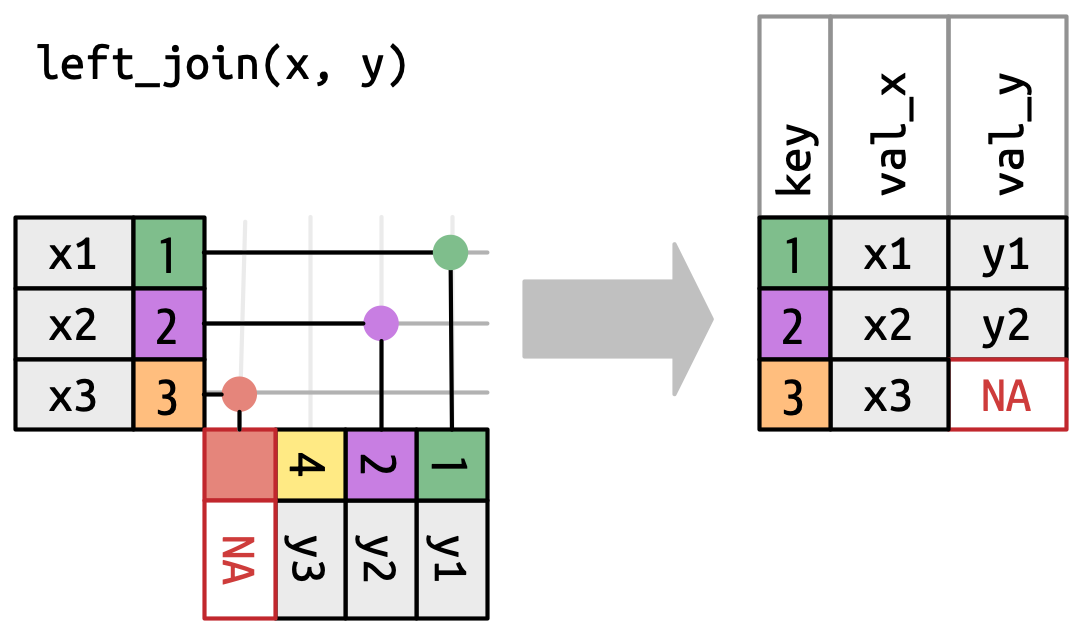
Left tibble keeps same numbers of rows.
Example with left_join()
left_join(subject_mood, coffee_drinkers,
by = join_by(subject == student))# A tibble: 187 × 6
subject condition gender mood_pre mood_post coffee_shots
<dbl> <chr> <chr> <dbl> <dbl> <dbl>
1 2 control female 81 NA NA
2 1 stress female 59 42 NA
3 3 stress female 22 60 NA
4 4 stress female 53 68 NA
5 7 control female 48 NA NA
6 6 stress female 73 73 NA
7 5 control female NA NA NA
8 9 control male 100 NA NA
9 16 stress female 67 74 NA
10 13 stress female 30 68 NA
# ℹ 177 more rowsThe missing subject 211 is unmatched and not returned
left_join(subject_mood, coffee_drinkers,
by = join_by(subject == student)) |>
filter(!is.na(coffee_shots))# A tibble: 3 × 6
subject condition gender mood_pre mood_post coffee_shots
<dbl> <chr> <chr> <dbl> <dbl> <dbl>
1 23 control female 78 NA 4
2 21 control female 68 NA 1
3 28 stress male 53 68 2Right-join
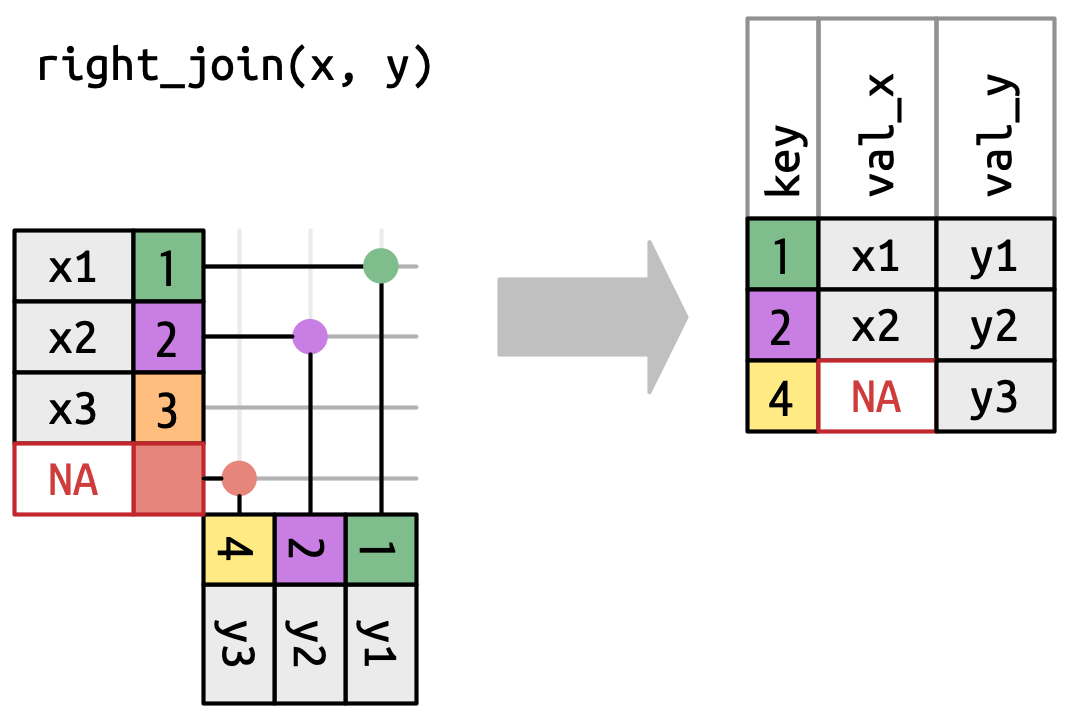
Right tibble matters
Example with right_join()
right_join(subject_mood, coffee_drinkers,
by = join_by(subject == student))# A tibble: 4 × 6
subject condition gender mood_pre mood_post coffee_shots
<dbl> <chr> <chr> <dbl> <dbl> <dbl>
1 23 control female 78 NA 4
2 21 control female 68 NA 1
3 28 stress male 53 68 2
4 211 <NA> <NA> NA NA 3The missing subject 211 is unmatched and returned with NA for left columns
Full-join
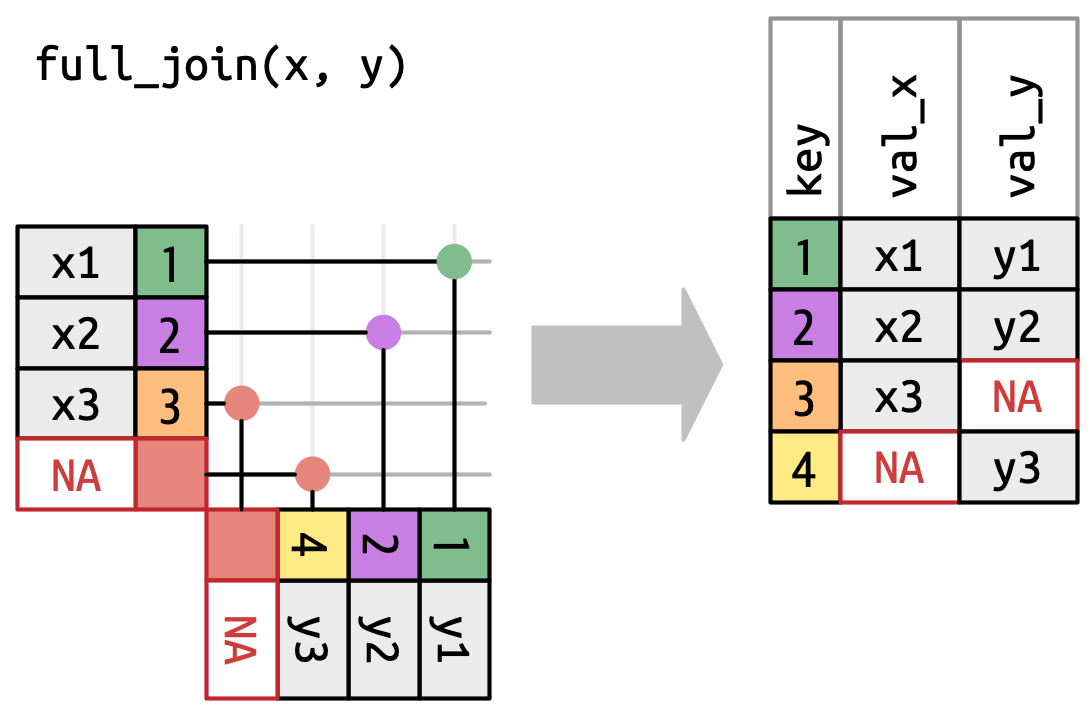
Number of rows = left + right
Example with full_join()
full_join(subject_mood, coffee_drinkers,
by = join_by(subject == student))# A tibble: 188 × 6
subject condition gender mood_pre mood_post coffee_shots
<dbl> <chr> <chr> <dbl> <dbl> <dbl>
1 2 control female 81 NA NA
2 1 stress female 59 42 NA
3 3 stress female 22 60 NA
4 4 stress female 53 68 NA
5 7 control female 48 NA NA
6 6 stress female 73 73 NA
7 5 control female NA NA NA
8 9 control male 100 NA NA
9 16 stress female 67 74 NA
10 13 stress female 30 68 NA
# ℹ 178 more rowsThe missing subject 211 is unmatched and returned with NAs
# A tibble: 4 × 6
subject condition gender mood_pre mood_post coffee_shots
<dbl> <chr> <chr> <dbl> <dbl> <dbl>
1 23 control female 78 NA 4
2 21 control female 68 NA 1
3 28 stress male 53 68 2
4 211 <NA> <NA> NA NA 3Filtering joins
Only the existence of a match is important; it doesn’t matter which observation is matched. This means that filtering joins never duplicate rows like mutating joins do
— Hadley Wickam
Filter matches in x, no duplicates
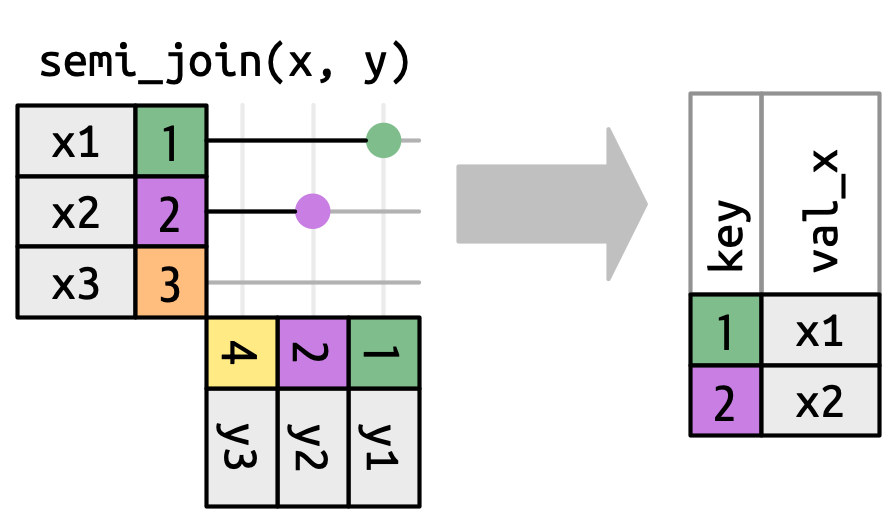
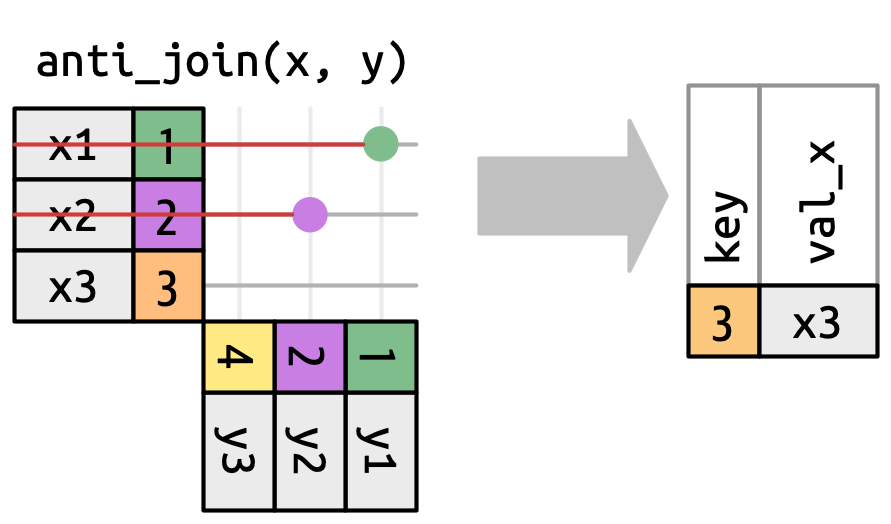
Extract what does not match
Cross join, Cartesian product
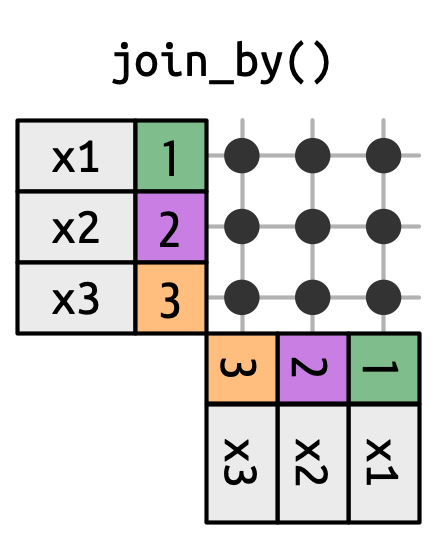
For permutations
# A tibble: 16 × 2
name.x name.y
<chr> <chr>
1 John John
2 John Simon
3 John Tracy
4 John Max
5 Simon John
6 Simon Simon
7 Simon Tracy
8 Simon Max
9 Tracy John
10 Tracy Simon
11 Tracy Tracy
12 Tracy Max
13 Max John
14 Max Simon
15 Max Tracy
16 Max Max