library(datasauRus)Datasaurus
This guided practical will demonstrate that the tidyverse allows to compute summary statistics and visualize datasets efficiently. This dataset is already stored in a tidy tibble, cleaning steps will come in future practicals.
Those squared questions are optional
datasauRus package
Check if you have the package datasauRus installed
Note
It should return nothing. If there is no package called ‘datasauRus’ appears, it means that the package needs to be installed. Use this in the console (will prevent the knit process otherwise):
install.packages("datasauRus")Explore the dataset
Since we are dealing with a tibble, we can type
datasaurus_dozenOnly the first 10 rows are displayed.
# A tibble: 1,846 × 3
dataset x y
<chr> <dbl> <dbl>
1 dino 55.4 97.2
2 dino 51.5 96.0
3 dino 46.2 94.5
4 dino 42.8 91.4
5 dino 40.8 88.3
6 dino 38.7 84.9
7 dino 35.6 79.9
8 dino 33.1 77.6
9 dino 29.0 74.5
10 dino 26.2 71.4
# ℹ 1,836 more rowsWhat are the dimensions of this dataset? Rows and columns?
- base version, using either
dim(),ncol()andnrow()
- tidyverse version
Assign the datasaurus_dozen to the ds_dozen name. This aims at populating the Global Environment
Using Rstudio, those dimensions are now also reported within the interface, where?
How many datasets are present?
- base version
TipTip
You want to count the number of unique elements in the column dataset. The character $ applied to a data.frame subset the column and convert the 2D structure to 1D, i. e a vector. The function length() returns the length of a vector, such as the unique elements
- tidyverse version
# n_distinct counts the unique elements in a given vector.
# we use summarise to return only the desired column named n here.
# we use English verbs and no subsetting characters, nor we change dimensions (keep a tibble)
summarise(ds_dozen, n = n_distinct(dataset))# A tibble: 1 × 1
n
<int>
1 13- even better, compute and display the number of lines per
dataset
TipTip
the function count in dplyr does the group_by() by the specified column + summarise(n = n()) which returns the number of observation per defined group.
Check summary statistics per dataset
Compute the mean of the x & y column. For this, you need to group_by() the appropriate column and then summarise()
TipTip
in summarise() you can define as many new columns as you wish. No need to call it for every single variable.
Compute both mean and standard deviation (sd) in one go using across()
What can you conclude?
Plot the datasauRus
Plot the ds_dozen with ggplot such the aesthetics are aes(x = x, y = y)
with the geometry geom_point()
TipTip
the ggplot() and geom_point() functions must be linked with a + sign
SolutionSolution
ggplot(ds_dozen, aes(x = x, y = y)) +
geom_point()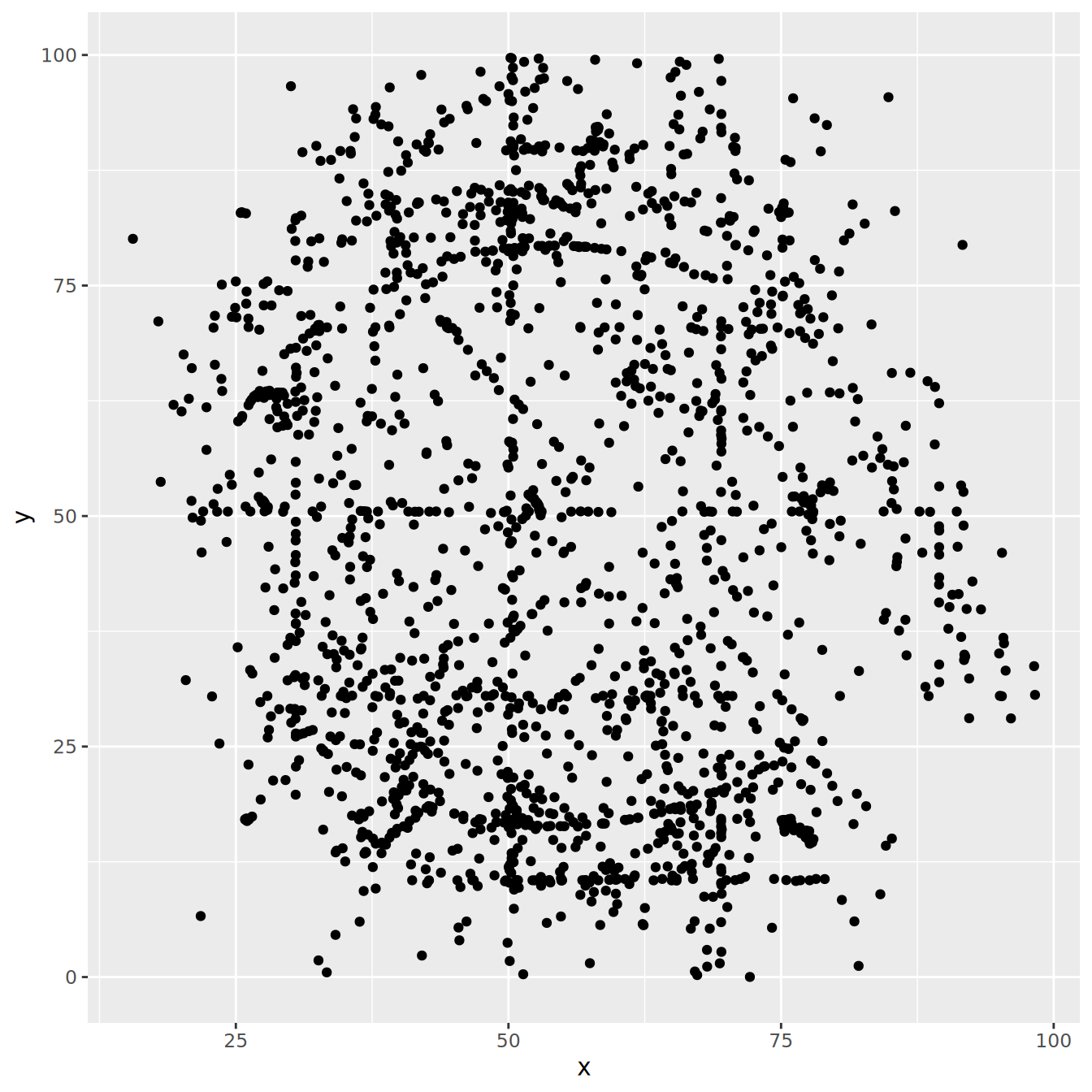
Reuse the above command, and now colored by the dataset column
SolutionSolution
ggplot(ds_dozen,
aes(x = x,
y = y,
colour = dataset)) +
geom_point()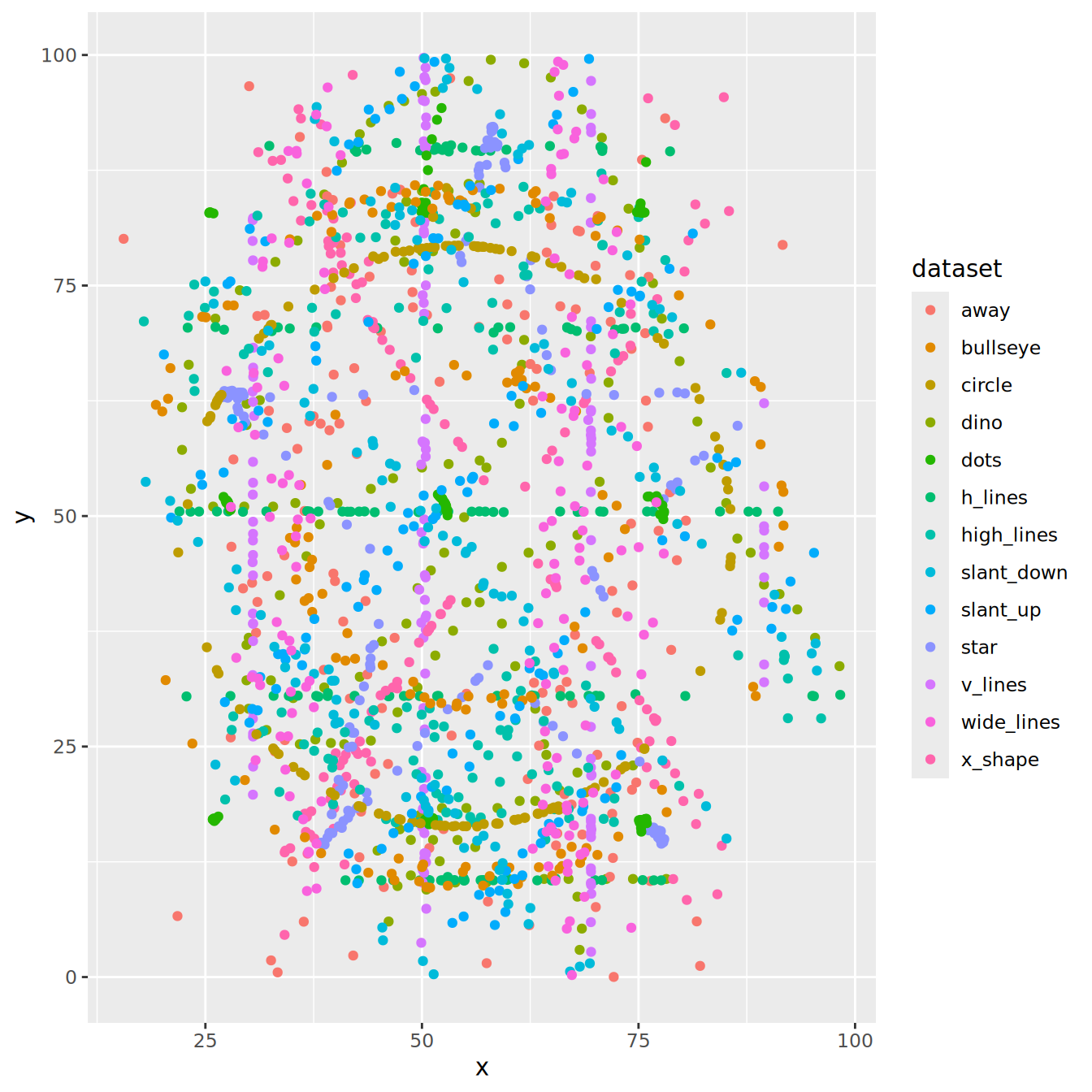
Too many datasets are displayed.
How can we plot only one at a time?
TipTip
You can filter for one dataset upstream of plotting
SolutionSolution
ds_dozen|>
filter(dataset == "away")|>
ggplot(aes(x = x, y = y)) +
geom_point()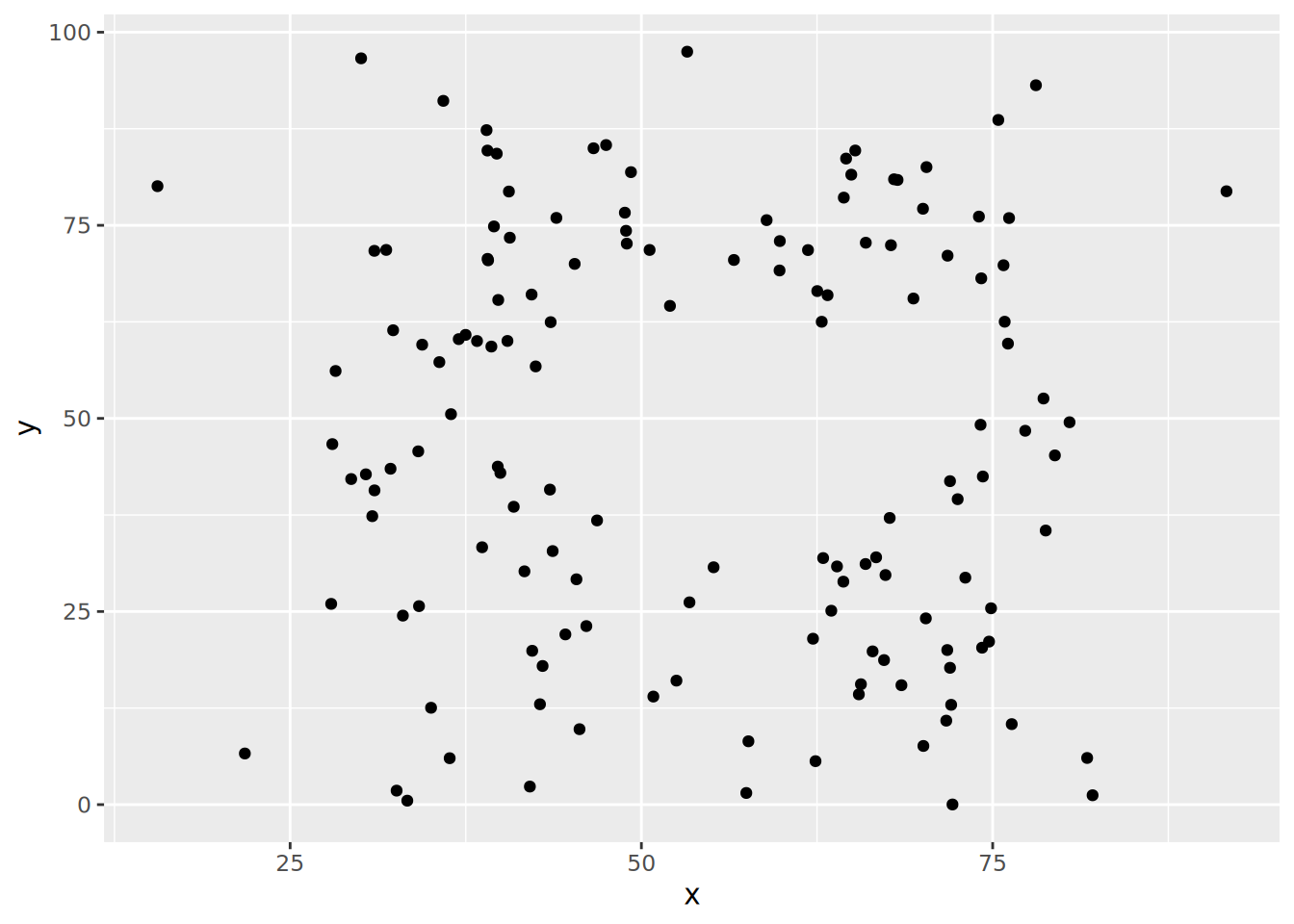
Adjust the filtering step to plot two datasets
TipTip
R provides the inline instruction %in% to test if there a match in the left operand with the right one (a vector most probably)
SolutionSolution
ds_dozen|>
filter(dataset %in% c("away", "dino"))|>
# alternative without %in% and using OR (|)
#filter(dataset == "away" | dataset == "dino")|>
ggplot(aes(x = x, y = y, colour = dataset)) +
geom_point()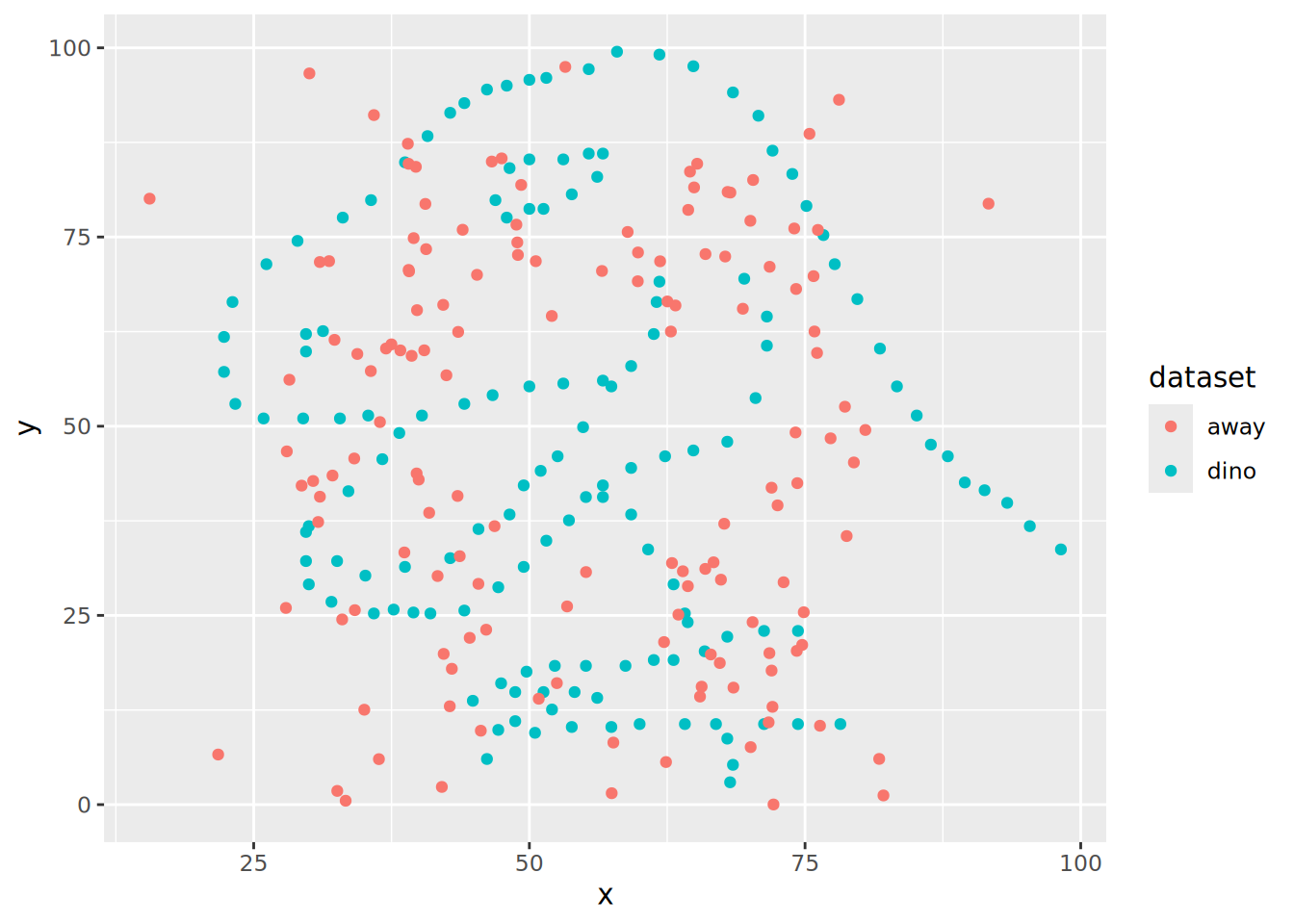
Expand now by getting one dataset per facet
SolutionSolution
ds_dozen|>
filter(dataset %in% c("away", "dino"))|>
ggplot(aes(x = x, y = y, colour = dataset)) +
geom_point() +
facet_wrap(vars(dataset))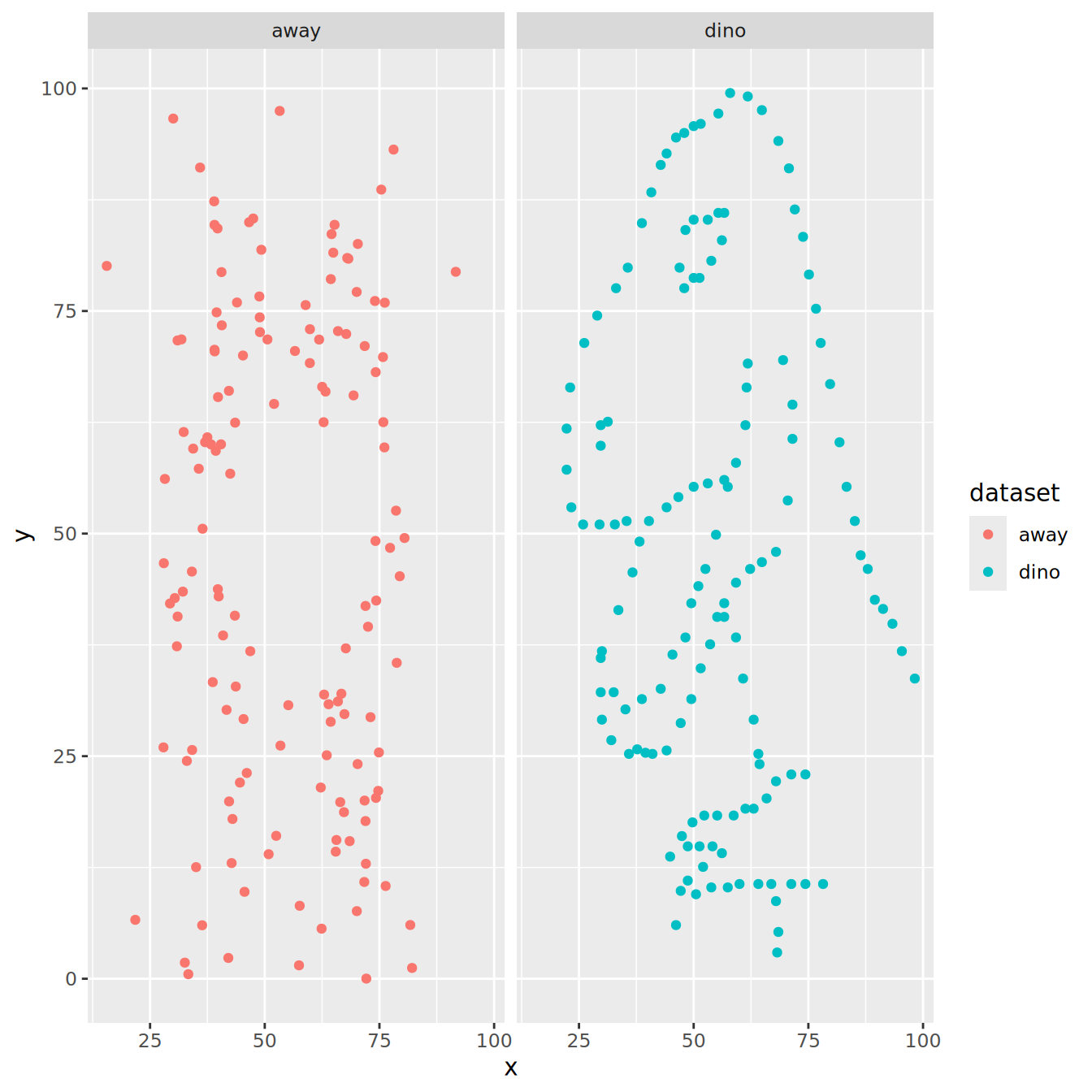
Remove the filtering step to facet all datasets
SolutionSolution
ds_dozen|>
ggplot(aes(x = x, y = y, colour = dataset)) +
geom_point() +
facet_wrap(vars(dataset), ncol = 3)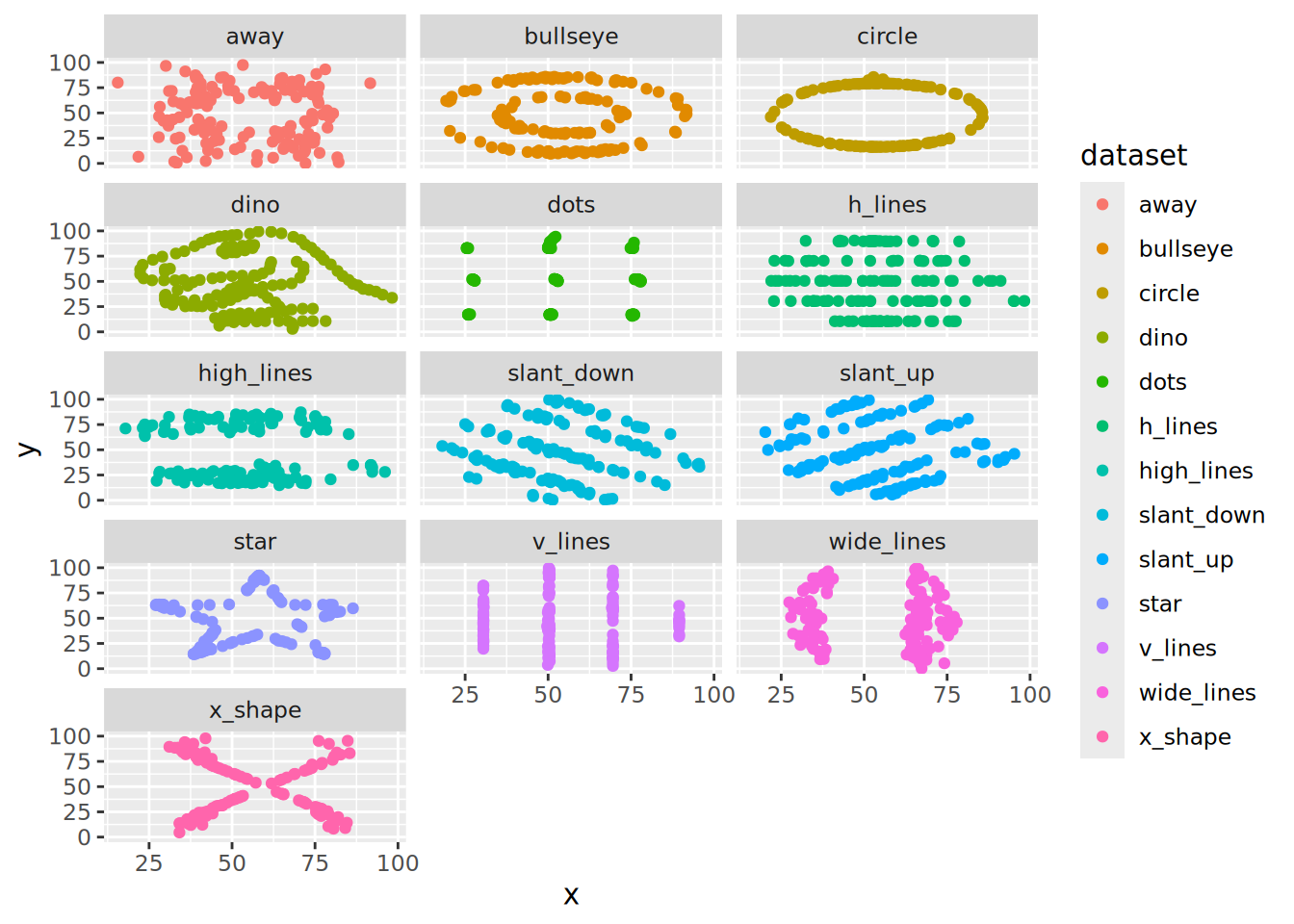
Tweak the theme and use the theme_void() and remove the legend
SolutionSolution
ggplot(ds_dozen, aes(x = x, y = y, colour = dataset)) +
geom_point() +
theme_void() +
theme(legend.position = "none") +
facet_wrap(vars(dataset), ncol = 3)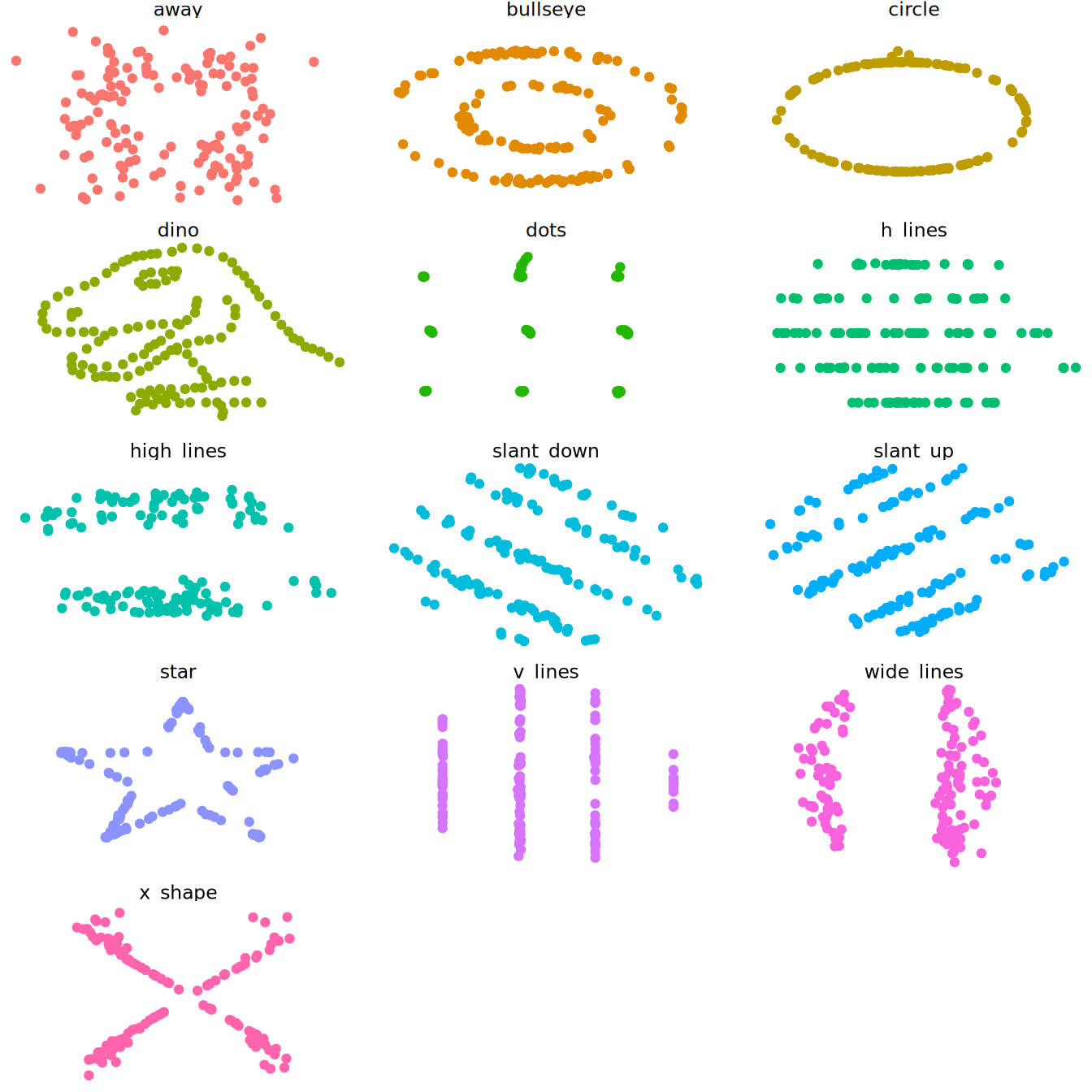
Are the datasets actually that similar?
Animation
Plots can be animated, see for example what can be done with gganimate. Instead of panels, states are made across datasets and transitions smoothed with an afterglow effect.
SolutionSolution

Conclusion
Never trust summary statistics alone; always visualize your data | Alberto Cairo
Authors
- Alberto Cairo, (creator)
- Justin Matejka
- George Fitzmaurice
- Lucy McGowan
from this post